Kunstig intelligente systemer
Kunstig intelligens (forkortes KI eller AI, fra Artificial Intelligence) er noe alle har hørt om, men som likevel kan være vanskelig å definere. (Hva er intelligens, for den saks skyld?)
Tankene går fort til sosiale medier, der de fleste er klar over at det brukes AI – og kanskje mistenker at vi på en eller annen måte blir manipulert.
Samtidig har vi også med oss den populærkulturelle fremstillingen av kunstig intelligens fra filmer som The Terminator, Blade Runner og Star Wars, der en AI er en robot eller et datasystem med menneskelignende intelligens – som kan tenke og handle på egenhånd, og som matcher (og vel så det) våre egne tross alt begrensede mentale evner.
Har algoritmene til Instagram og TikTok noe med C3PO eller Skynet å gjøre? Eller hva er egentlig kunstig intelligens – reelt sett?
Systemer som oppnår et mål basert på data
Kunstig intelligens er enkelt og greit en samlebetegnelse. Akkurat som at epler og pærer begge er frukt, kan to forskjellige dataprogrammer begge være regnet som kunstig intelligens, selv om de gjør vidt forskjellige ting og baserer seg på ulike underliggende teknikker.
En vanlig forståelse av kunstig intelligens er datasystemer eller programmer som kan motta og behandle data fra ulike kilder og – med noen grad av selvstendighet – utføre handlinger som maksimerer sjansene for å oppnå et gitt mål.
Norges nasjonale strategi for kunstig intelligens har følgende definisjon: «Kunstig intelligente systemer utfører handlinger, fysisk eller digitalt, basert på tolkning og behandling av strukturerte eller ustrukturerte data, i den hensikt å oppnå et gitt mål. Enkelte AI-systemer kan også tilpasse seg gjennom å analysere og ta hensyn til hvordan tidligere handlinger har påvirket omgivelsene».
Når du hører om kunstig intelligens i sammenheng med teknologi og data, dreier det seg svært ofte mer spesifikt om maskinlæring. Maskinlæring er en av flere underkategorier av kunstig intelligens, og handler om systemer som kan lære fra data.
Hva er maskinlæring?
Du har lært hva algoritmer er. Vi har skrevet at noen algoritmer omtales som «smarte»; de brukes til å trene og kjøre maskinlæringsmodeller. La oss se hva dette faktisk betyr.
Algoritmer ligger bak absolutt alle dataprogrammer. Også maskinlæringsalgoritmer er altså avhengige av trinnvise og presise instruksjoner for hva som skal skje i en bestemt situasjon; selv om vi kaller det «kunstig intelligens» dreier det seg ikke om noen form for refleksjon, improvisasjon eller selvbevissthet.
I stedet er det snakk om å bruke metoder og verktøy fra matematikken og statistikken til å lage maskinlæringsalgoritmer eller modeller som kan endre seg og tilpasse seg omstendighetene og tilgjengelige data.
Først må vi bestemme den konkrete oppgaven modellen skal løse – som å filtrere ut søppelpost, spille sjakk eller forutsi hvordan salget i bilbutikken vil være i de neste månedene. Maskinlæringsalgoritmen gis deretter bestemte data å jobbe med som brukes til å «trene» modellen til den bestemte oppgaven.
Kanskje klarer ikke modellen å skille mellom legitim e-post og søppelpost til å begynne med. Men den kan også oppdateres (trenes) ved hjelp av flere og ferskere data, som betyr at den potensielt kan tilpasse seg for å løse oppgavene sine på stadig bedre måter.
Her ser vi også at maskinlæring er problemspesifikt. En modell kan trenes til å navigere en selvkjørende bil i trafikken, foreslå beste kjørerute, gjennomgå dokumentasjon til en lånesøknad eller automatisk fylle inn felter i en faktura der den finner de nødvendige dataene. Hver modell lages for å være best mulig på sin spesifikke ting – men kan ikke plutselig stoppe opp og bestemme seg for å gjøre noe helt annet.
Den typen AI som ligner menneskelig intelligens – altså Hollywood-versjonen av AI – er riktignok en visjon også i virkeligheten. Dette kalles kunstig generell intelligens (eller Artificial General Intelligence, AGI). Men det er en visjon som i skrivende stund er langt ifra oppnåelig, og noe helt annet enn maskinlæring.
Eksempel
Alien eller Mamma Mia?
Et typisk eksempel på bruk av maskinlæring er anbefalingene du får hos ulike strømmetjenester. Her vil modellene foreslå innhold basert på hva du liker å se eller høre.
Si at du elsker science fiction, men avskyr flåsete romantiske komedier. Når du setter på The Terminator én kveld og Blade Runner den neste, vil anbefalingsmodellen til strømmetjenesten kunne gjenkjenne et mønster, og i neste omgang foreslå at du setter på Alien eller The Matrix. I stedet for at forsiden din tapetseres med Mamma Mia og My Big Fat Greek Wedding, som du ikke er interessert i.
Målet algoritmen er satt til å utføre i dette eksempelet, er å gi best mulige forslag til innhold tilpasset hver enkelt brukers preferanser, vaner og smak. Jo bedre algoritmen er laget, og jo mer data den har å jobbe med basert på din og andre brukeres vaner og handlingsmønstre, dess bedre kan algoritmen bli på å gi deg forslag du faktisk liker.
Det overordnede målet er å maksimere sjansene for å holde deg klistret til skjermen – og i neste omgang fortsette å betale abonnementet ditt.
Slik trenes modellene
Det finnes mange ulike typer maskinlæringsalgoritmer, men det er vanlig å gruppere dem i tre kategorier: veiledet læring, ikke-veiledet læring og forsterkende læring.
Den enkleste og mest utbredte av disse, er veiledet læring, så vi ser på den først.
Veiledet læring
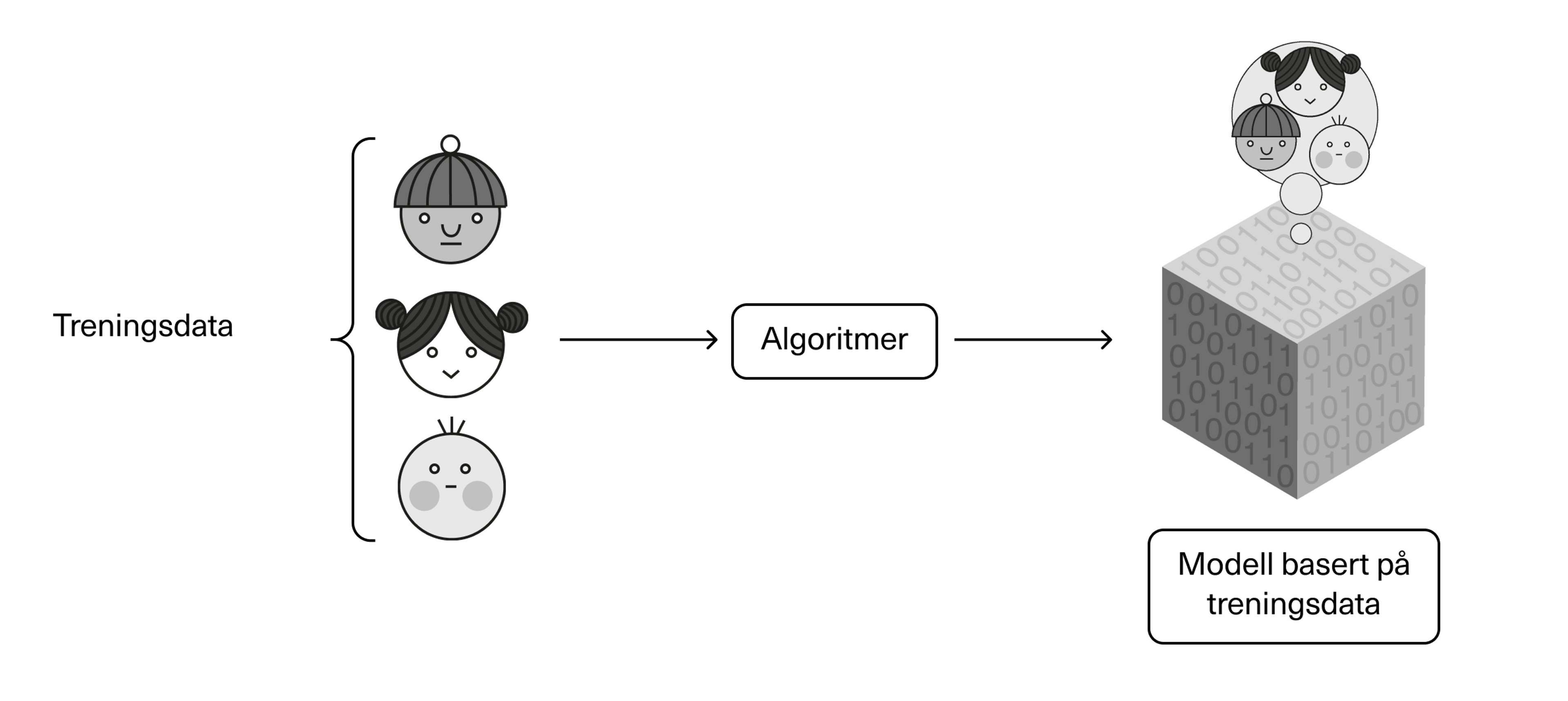
Når vi trener opp maskinlæringsmodellen, bruker vi det vi kaller treningsdata. Hvis det eksempelvis er snakk om en modell for å filtrere ut søppelpost, kan treningsdataene bestå av titusener, kanskje millioner av eksempler på e-poster – både legitime og spam – som modellen skal lære å oppdage forskjellen på.
Under veiledet læring gis algoritmen et datasett som både inneholder dataene (input) og informasjon om hva hver enkelt data representerer (output). Algoritmen sitter altså selv på «fasiten» for hva som er søppelpost og ikke. Modellen skal her lære seg en regel som bestemmer hvordan nye input (reelle data) blir koblet til mulige output.
Et annet eksempel kan være at maskinlæringsalgoritmen trenes opp ved hjelp av massevis av bilder av elefanter og giraffer, hvor den blir fortalt hvilke bilder som er av elefanter og hvilke bilder som er av giraffer, for å lære å forstå forskjellen på dem.
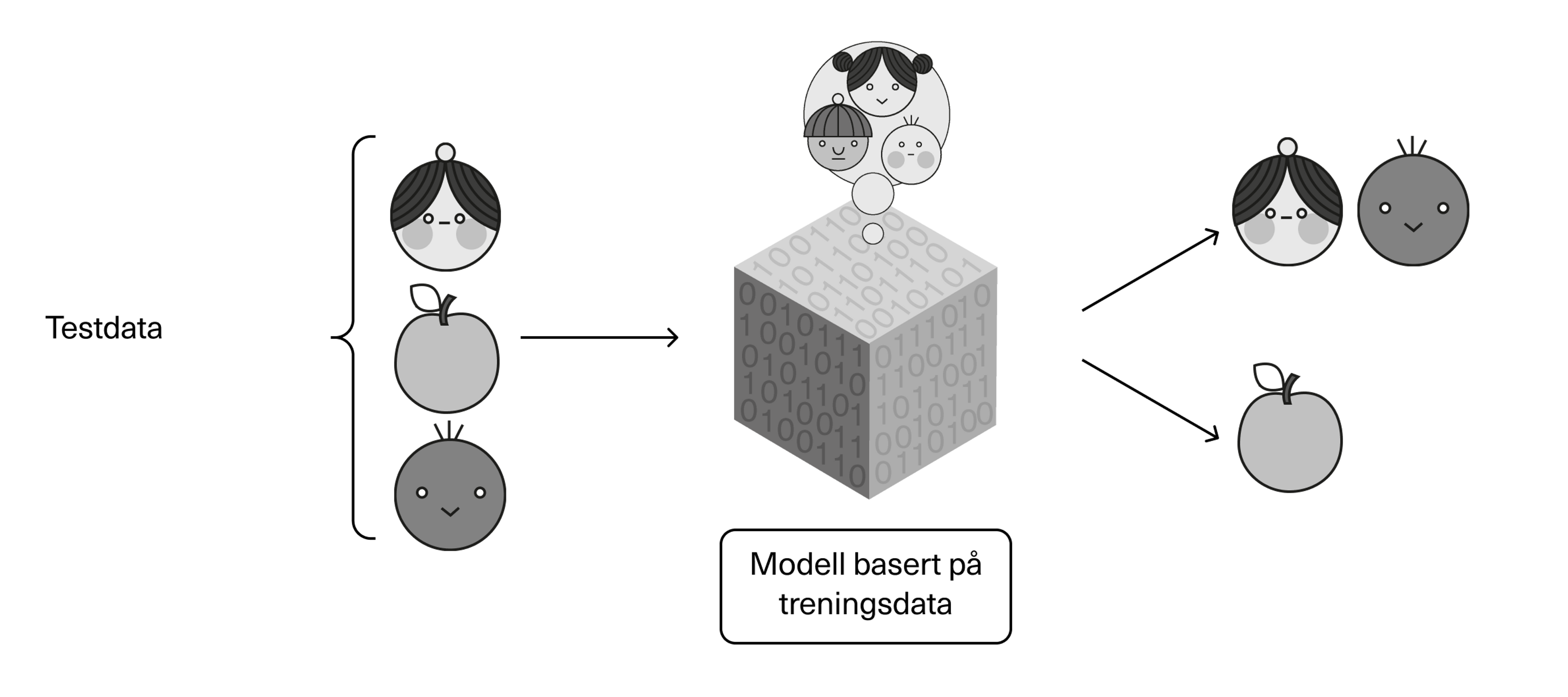
Når treningen er fullført, brukes testdata – data som algoritmen ikke har sett før – for å se hvor presis modellen faktisk er blitt. Her brukes helt nye og ukjente bilder av elefanter og giraffer, som ikke var del av treningen. Når vi tester modellen med et det nye datasettet, kan vi med andre ord finne ut om den har lært det den skal og fungerer som ønsket.
Når modellen senere settes i produksjon – altså tas i reell bruk, i dette tilfellet i et program for bildegjenkjenning – vil vi kunne velge at den skal kunne fortsette å lære av de nye dataene og utvikle seg videre. Det er imidlertid viktig at dette overvåkes slik at vi sikrer at modellen faktisk blir bedre og ikke lærer feil ting.
Ikke-veiledet læring
Ved ikke-veiledet læring ser algoritmen etter strukturer og mønstre i dataene på egen hånd. I motsetning til veiledet læring får ikke algoritmen informasjon om hva som menes med dataene (output) under opptreningen. I stedet vil vi at modellen selv skal gjenkjenne grå dyr med snabel og rare gule dyr med lang hals som ulike dyr, og gruppere dem hver for seg.
Forsterkende læring
Algoritmen blir ikke instruert i hvordan den skal løse oppgaven, men får belønning og straff for gode og dårlige resultater. Et typisk eksempel er en maskin som kun får oppgitt et mål – å vinne i sjakk – men som ikke blir fortalt hvilke brikker som er mest verdt eller hva som regnes som et lurt trekk. Dette målet prøver maskinen å oppnå gjennom prøving og feiling.
Med maskinlæring som verktøy kan vi løse problemer på andre måter – og løse andre problemer – enn hva vi mennesker er i stand til på egenhånd. Dette åpner opp for mange spennende muligheter. Algoritmene er samtidig prisgitt dataene de har å jobbe med.
Nok data – og god nok data – er derfor en forutsetning for å lykkes med maskinlæring.
Data blir det stadig mer av og de kommer fra flere ulike kilder, og det er blant annet som et resultat av tingenes internett, som er det neste vi skal se på. Vi skal også senere se nærmere på kunstig intelligens og maskinlæring, i kapittel 5.