Nøkler i databaser
Det er et viktig aspekt ved relasjonsdatabaser som vi ikke har vært inne på ennå. Nemlig det som kalles nøkler.
Hensikten med disse nøklene er kort og godt å gi hver oppføring i databasen det som tilsvarer et unikt fingeravtrykk. Dette hjelper oss med å identifisere disse og skille dem fra andre oppføringer.
Det er to varianter av nøkler vi skal se på her: det som kalles primærnøkkel og fremmednøkkel.
Hva er en primærnøkkel?
For å få relasjoner til å fungere i databaser – altså rent teknisk, for å kunne slå opp og finne data i en database – er det nødvendig å entydig identifisere hver enkelt instans i entitetene.
Attributter kan brukes til dette. Men for at en attributt skal kunne brukes som primærnøkkel, må den tilfredsstille tre krav:
- Den må være unik
- Den må ikke kunne være tom (vi kaller dette en NULL-verdi)
- Den må aldri endres
Entydige attributter i en entitet som oppfyller disse kravene er entitetens kandidatnøkler, og en av disse velges som primærnøkkel.
Hvis det ikke finnes noen slik attributt i entiteten, må en opprettes – ofte i form av et løpenummer, som for eksempel et kundenummer i en butikk, eller et personnummer relatert til statsborgerskap.
Dette blir enklere å forstå gjennom et eksempel. Vi kan vende tilbake til det tidligere eksempelet med statsborger og pass.
Én-til-én: Statsborger og pass
Et passnummer er unikt, kan ikke være null, og endres ikke. Det kan derfor brukes som primærnøkkel. Dette er i praksis en egen kolonne som vi legger inn i denne entiteten, som er unik for hver rad med data.
Passnummeret kan her brukes som primærnøkkel for selve passet – men ikke for statsborgeren. Vi husker at denne kardinaliteten er ikke-obligatorisk (statsborgeren må ikke ha et pass).
I dette enkle eksempelet har vi bare én attributt i statsborger-entiteten, nemlig navn. Det kan kanskje virke logisk å bruke navnet som primærnøkkel, men det går ikke. Flere personer kan ha samme navn, og det er mulig å endre navn i løpet av livet.

Vi utvider derfor entiteten statsborger med personnummer – som er unikt, aldri null, og ikke mulig å endre.
Så utvider vi entitetene med en kolonne for nøkler, og navngir personnummer og passnummer med PK (Primary Key - det engelske navnet på primærnøkkel).
Nøkkelen til å lage relasjoner
Vi har nå opprettet en primærnøkkel for hver entitet. Men hvordan knytter vi disse egentlig sammen med en relasjon?
Til dette gjør vi noe som kalles nøkkelvandring. Vi flytter PK (personnummer) fra statsborger-entiteten til pass-entiteten, der vi navngir det FK (Foreign Key, igjen engelsk, som vi ville kalle fremmednøkkel).
For å være tydelig: Passet har allerede sin egen primærnøkkel (passnummer), men vi legger også til en fremmednøkkel (statsborgerens personnummer, som på sin side er primærnøkkelen til denne andre entiteten). På denne måten kan vi se helt entydig hvem passet tilhører.
Det er dette som gjør det mulig å følge relasjoner mellom instanser av entiteter; i dette tilfellet altså hvilket pass som tilhører hvilken person.

I en-til-en relasjoner er det fullt mulig at disse nøklene kan vandre begge veier. Men i og med at ikke alle personer har et pass, men alle personer som har et pass har et personnummer, er det logisk å bare flytte personnummeret inn og legge det inn sammen med passnummeret – for den vil da aldri kunne være null under statsborgeren.
Én-til-flere: Person og bok
La oss ta et annet eksempel, nemlig en-til-mange-relasjonen der en person kan eie 0, 1 eller mange bøker.
Hverken person eller bok har attributter som er unike. Bøker så vel som personer kan ha samme navn – og navn kan endres. Vi merker oss også at det kan være null bøker knyttet til en person.
I denne relasjonen har vi derfor ingen nøkkelkandidater slik det står akkurat nå.

Vi må derfor finne og introdusere attributter som unikt identifiserer disse to entitetene. Vi løser det ved å utvide person-entiteten med det vi kaller p-ID.
Vi kunne ha brukt personnummer, men hvis dette er en bokhandel, en bokklubb eller en nettside der en kan registrerer alle bøkene sine og diskutere med andre entusiaster, unnlater vi å bruke personnummeret fordi det er sensitive data. I stedet får vi rett og slett databasen til å lage en unik ID for hver person som registreres. Det handler om personvern.
Dette er et eksempel på det vi kan kalle syntetiske attributter. Disse kan vi generere selv, eller databasen kan autogenerere dem. Førstemann kan bli nummer 1, neste blir nummer 2, og så videre.
Boken har allerede en unik attributt, nemlig ISBN-nummeret som alle bøker som publiseres i verden får. Det er et unikt nummer og det endres aldri. ISBN-nummeret er offentlig tilgjengelig informasjon, og kan brukes som det er.
Tilsvarende som i eksempelet med statsborger og pass, flytter vi personens ID over til boken, og bruker den som en fremmednøkkel. Da blir det mulig å liste opp alle bøker som har den person-ID-en liggende inne som en fremmednøkkel – eller med andre ord å finne alle bøkene som eies av personen.
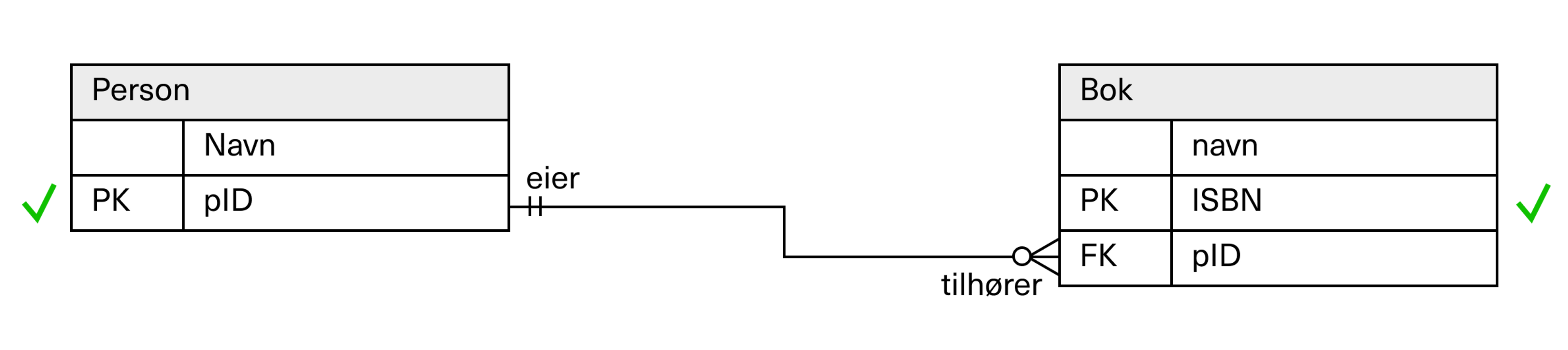
I en-til-mange-relasjoner må nøklene vandre fra én-siden til mange-siden, og brukes som fremmednøkkel der.
Hvis nøkkelvandringen gikk den andre veien, ville det generert et lang og uavgrenset rekke fremmednøkler – i dette tilfellet hundrevis, kanskje tusenvis av ISBN-nummer – inne i person-entiteten. Dette ønsker vi ikke, det er ikke slik relasjonsdatabaser skal fungere.
Vi vil ha kun én instans av en nøkkel under hver instans i entiteten.
Mange-til-mange: Forbruker og resirkuleringspunkt
Hvis vi ikke kan flytte en drøss med nøkler over i en annen entitet … hvordan er det da med mange-til-mange-relasjoner? Godt spørsmål, oppvakte leser!
Her finnes det en løsning, og for å vise den kan vi ta eksempelet med forbruker og resirkuleringspunkt.
Hverken forbruker eller resirkuleringspunkt har attributter som er unike. I resirkuleringspunkt-entiteten har vi lagt inn type som attributt, men vi kan ikke bruke type som primærnøkkel, for det er mange punkter med samme type.

Her ser vi forresten – og dette er en liten digresjon fra eksempelet – at type burde skilles ut i en egen entitet. Attributtdata som «papir og papp», «plast», «glass og metall» og så videre er felles for mange punkter – akkurat som at postnummer er felles for mange gateadresser. Som du husker, ønsker vi å unngå redundans og feil i databasen, og derfor bør disse opprettes som egne entiteter.
Uansett, tilbake til nøklene: For forbruker-entiteten lager vi det vi kaller for fID, forbruker-ID.
Dette kan være generert av systemet, eller det kan være et unikt kundenummer. Igjen vil vi unngå å bruke personnummer, med tanke på personvern. Den unike ID-en til resirkuleringspunktet kaller vi eID.

Men i dette eksempelet – hvor skal nøklene vandre?
Skal vi ta alle forbrukerne som bruker et resirkuleringspunkt og legge dem under resirkulering-entiteten? Det går ikke. Da blir det potensielt kjempemange gjentakelser av forbrukere. Av samme grunn kan vi ikke ta nøkkelen fra alle resirkuleringspunkt som en forbruker har brukt, og legge det under den entiteten.
I mange-til-mange relasjoner kan ikke nøklene vandre direkte fra noen av sidene til den andre. Det vil i vårt eksempel medføre repetisjon av alle forbrukere eller av alle punkter – og det kan vi ikke gjøre. Men vi har en løsning på det i relasjonsdatabaser.
Løsningen er å legge til en ny entitet, som vi setter mellom de to. Vi kaller det for en oppløsningsentitet.
Denne entiteten representerer en konkret resirkulering foretatt av en forbruker, på et konkret resirkuleringspunkt og på et eksakt tidspunkt.
Vi lar de to primærnøklene (PK) vandre som Foreign Key (FK) til oppløsningsentiteten, som vi kaller resirkulering. En forbruker kan nå utføre mange resirkuleringer, og mange resirkuleringer kan utføres på ett resirkuleringspunkt. Her har vi også lagt til en ny attributt – tidspunkt – og lagt det i oppløsningsentiteten.

Oppløsningsentiteten har ingen PK, den identifiseres unikt med begge FK – en fra hver av entitetene i mange-til-mange relasjonen. Primærnøkkelen til oppløsningsentiteten vil altså alltid være kombinasjonen av de to fremmednøklene som har vandret dit fra hver side. Tidspunktet må også være med i nøkkelen, for å unngå duplikater.
Ved å gjøre et oppslag her nå, kan vi se hvilke resirkuleringspunkt (eID) som inngikk i en resirkulering der en forbruker (fID) gjorde en resirkulering. Kombinasjonen av disse to fremmednøklene vil vise en unik person som har puttet resirkuleringsmateriale inn i et spesifikt punkt på et spesifikt tidspunkt.
Fjo! Og med det har vi brått en temmelig god forståelse av hvordan en database fungerer. Ikke verst? Med det skal vi også runde av kapittelet, og gå over til å se på hvordan vi nå faktisk kan ta disse strukturerte dataene i bruk.