Dataisfjellet
Mulighetene i data utnyttes i dag fremfor alt kommersielt – og for politiske formål (tenk bare på Cambridge Analytica-skandalen).
På samme måte som at du bygger dine egne IKEA-hyller, er du også en medprodusent av de kommersielle digitale tjenestene du bruker. IKEA kan selge hyllene sine rimelig fordi du selv står for monteringen. Du stiller i praksis opp med gratis arbeidskraft. På samme måte bidrar du med gratis arbeidskraft i den digitale økonomien i form av at du genererer data for kommersielle aktører.
Søk, sosiale medier, nettsamfunn, kart og andre digitale verktøy er ofte ikke bare rimelige, men gratis. Det er som regel fordi du produserer data for dem.
Dataene brukes i neste omgang til å hente ut innsikter, videreutvikle tjenesten og bygge nye produkter som investorer, partnere, kunder, annonsører og andre er villige til å betale for.
Ikke bare kommer dataene fra deg, det er ofte også nettopp deg de handler om. Du har kanskje hørt det sagt at dersom noe er gratis, er det fordi det er du som er produktet. Digital informasjon om kunder pluss en handlingsdyktig forretningsmodell er i mange sammenhenger så godt som gull.
Dette skal vi se mer på snart. Men først: La oss se nærmere på hvordan alle disse dataene kan være usynlige for oss – når vi praktisk talt svømmer i dem.
Isfjellmodellen
Det kan være vanskelig å se for seg hvor mye og hvilke data som sirkulerer rundt oss til en hver tid, og som produseres når vi interagerer med digital teknologi. Isfjellmodellen kan gjøre det enklere å forstå.
De fleste av dataene vi produserer er i utgangspunktet usynlige for oss. De blir til i bakgrunnen av det vi gjør og der vi er, uten at vi merker det. Men de digitale sporene er der like fullt, og følger oss gjennom dagen i det vi gjør.
Vi ser bare toppen av dette data-isfjellet. Som kjent er det bare toppen av isfjellet som er synlig, mens mesteparten ligger under vann. På samme måte er det med data.
Isfjellmodellen er i utgangspunktet en kommunikasjonsmodell brukt av Sigmund Freud. Den beskriver at kommunikasjon mellom mennesker er mye mer komplisert enn vi tror. På overflaten har du det vi sier – saklige ting, som fakta og så videre. Men størsteparten av kommunikasjonen skjer under overflaten: det rommer hele situasjonen, stemninger, hvordan vi føler oss, alt det komplekse knyttet til psykiske prosesser som vi ikke er bevisste på.
Den samme modellen kan brukes som en metafor for å beskrive interaksjonen mellom mennesker og maskiner – som også er mye mer kompleks enn det vi tror.
Vi kan skille mellom data i tre kategorier: rådata, analytiske data og funksjonelle data.
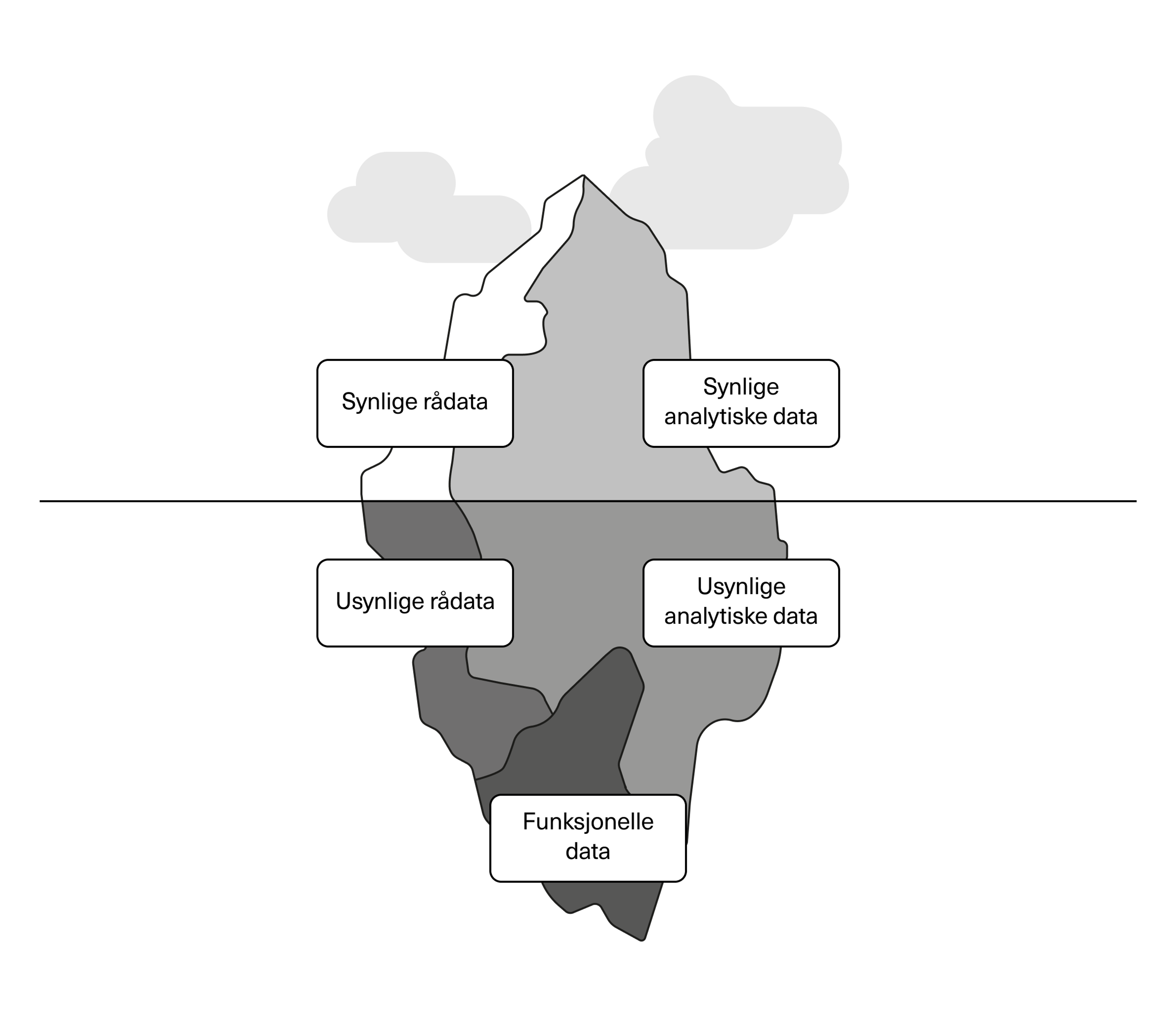
Rådata og analytiske data kan være både synlige og usynlige, som du ser i figuren, mens funksjonelle data ligger under overflaten. La oss se nærmere på hva hver av disse innebærer.
Rådata
Med rådata menes ganske enkelt data som ikke (ennå) er bearbeidet for noe spesielt formål. Litt enkelt kan vi si at dette er data som bare har gjennomgått første del av livssyklusen du ble kjent med i forrige seksjon; de er lagret, men ikke for eksempel bearbeidet for videre analyse.
Tenk på alle data som er synlige for oss og som vi mener å ha kontroll over når vi interagerer med digitale maskiner. Det kan være en tweet, en e-post, et blogginnlegg, et utfylt skjema, en snap som du sender til en venn, en melding på en meldingsplattform eller en Youtube-video. Dette er rådata.
Mer spesifikt er alle disse tingene eksempler på det vi kan kalle innholdsdata. Innholdsdata er informasjons- og kommunikasjonsinnhold som vi utveksler med andre mennesker gjennom bruken av maskiner, applikasjoner og plattformer, og som gjerne er multimediale (lyd, tekst, bilde, video og så videre).
En annen type rådata er sensordata, for eksempel data om hjerterytmen og bevegelsene dine som registreres av en smartklokke.
Rundt alle disse interaksjonene oppstår det også metadata. Metadata er i denne sammenhengen beskrivende data som oppstår i en gitt kontekst når vi samhandler med digitale enheter. I tillegg til selve innholdet i tweeten og e-posten (innholdsdata) vil det for eksempel genereres metadata slik som tidspunkt hvor du sendte tweeten, posisjonsdata, antall brukte tegn, hvilken enhet som er brukt, hvilken nettleser og mer.
Noen metadata er synlige for oss, mens andre ligger under overflaten. Det er spesielt slike metadata som inngår i videre analyseprosesser. Det tar oss over i neste kategori.
Analytiske data
Når du ser på Netflix, overføres det åpenbart innholdsdata – selve serien eller filmen. Like åpenbart er det at Netflix vet hva du ser på.
Utover dette er det også mye annen data som sendes til Netflix: hvor og når du ser, hvilken enhet du bruker, videokvalitet, hastigheten på nettverket, og så videre. Ikke minst fanger de opp hvor du pauser eller stopper, hvor du spoler tilbake og ser noe på nytt, hvilke sjangere du foretrekker, når om dagen du ser på film – og mye, mye mer. Slik metadata om bruken din danner grunnlaget for å lage en profil om deg som kan avsløre informasjon om din atferd, dine sinnstilstander og rutiner.
Slike loggfiler og metadata blir automatisk produsert når vi som personer samhandler med digitale enheter, men også når digitale enheter samhandler med hverandre – som robotstøvsugeren din, et lesebrett eller en smart-TV. I disse loggfilene finnes det informasjon som gir en idé om hvordan enheten oppfører seg eller blir brukt. Det kan igjen brukes til både analyser og diagnostiske formål.
Noen metadata er synlige og deles med oss. For eksempel når en sender e-post, står det kanskje «sendt fra min Huawei» eller «sendt fra iPhone» helt nederst. Dette er metadata, og det kan i seg selv være verdifull informasjon: En iPhone er typisk dyrere enn en Huawei, og det sier noe om avsenderen. Også ting som når e-posten er sendt, avsenderens posisjon og hvilken e-postklient som er brukt, er metadata – og kan settes sammen på en måte som muliggjør videre analyse.
Vi må påpeke at det selvsagt ikke utelukkende er ting som loggfiler og metadata det er mulig å analysere. Rådata i form av innholdsdata kan for eksempel også analyseres via statistiske teknikker og maskinlæringsteknikker. Når du sender en e-post til kundeservice i en bedrift, kan det for eksempel tenkes at bedriften bruker teknologi for å analysere meningsinnholdet i e-posten, for å kartlegge om det er positivt eller negativt ladet (det å systematisk gjøre dette ved hjelp av kunstig intelligens kalles sentiment analysis eller opinion mining).
Funksjonelle data
Nederst i isfjellet finner vi funksjonelle data. Funksjonelle data er data som er nødvendige for at maskiner skal kunne kommunisere med hverandre, og for at applikasjoner og programvare skal fungerer.
Her snakker vi egentlig om data som utveksles via protokoller, for eksempel for å identifisere en bruker på et nettsted. Protokoller – som du vil lære mer om i neste kapittel – er rammeverket som gjør det mulig at utveksling av informasjon kan finne sted.
Dette er i utgangspunktet ren maskinkommunikasjon. Det vil likevel ikke si at dette ikke kan være interessant for mennesker, eller brukes i andre sammenhenger. For eksempel kan politi og sikkerhetsmyndigheter være interesserte i funksjonsdata fra en mobiltelefon som kommuniserer med nettverket om hvor den befinner seg, hvilket nettverk den er logget inn i, og så videre.
De ulike nivåene av data i isfjellmodellen kan du kjenne igjen når du blir bedt om å akseptere informasjonskapsler (cookies) på en nettside. Hvis du velger «Kun nødvendige cookies», får ikke nettstedet samle analytiske data om deg. Men du kan ikke avvise funksjonelle data, for da ville nettsiden rett og slett sluttet å fungere.
Innsikt
Hva betyr dette for deg og meg?
Vi begynte emnet med å si at vi er produsenter og brukere av data – som tannhjul i den store digitale økonomiske motoren. Isfjellmodellen beskriver denne situasjonen fra et praktisk, ikke et teknisk, perspektiv. Den er ment for å gi en forestilling om hvordan datainnsamling fungerer, og synliggjøre prosesser som for de fleste ikke er synlige.
Det er i vår interesse å dele en del data; det muliggjør fremskritt og det er noe samfunnet som helhet tjener på. For eksempel gir det mer effektiv samhandling, mer automatisering, mer støtte til jobbene våre og funksjoner som samfunnet trenger. Tjenester som Helsenorge og Statens lånekasse har også blitt mye smidigere.
Men det er også utfordringer med at disse tingene foregår i det skjulte. Sett fra et personvernperspektiv er det problematisk at en ikke vet hvilke data man sprer; det deles anonyme data som du ikke blir fortalt at finnes, eller om blir bearbeidet og brukt av noen. Selv om data om oss anonymiseres, kan vi likevel ofte identifiseres under gitte betingelser. Et enkelt eksempel: Hvis en app viser en rekke løpeturer som starter på samme adresse, skal det ikke mye fantasi til for å finne ut hvem det gjelder. Slike treningskart er faktisk blitt brukt til å avsløre hemmelige militærbaser!
Når du ikke vet hvem som har tilgang på dataene dine, blir du sårbar på en ny måte. Vi beskyttes til en viss grad av lover og regler, men utviklingen skjer så raskt at selv eksperter har vanskelig for å se hva som er mulig å gjøre med dataene vi legger igjen. Du kan gjøre visse ting for å gjemme deg – som å bruke VPN, eller slå av lokasjonsdata på mobilen – men å være helt inkognito er praktisk talt umulig med mindre du vil bo i skogen og leve av jakt og fiske.
Så lenge du lever som normalt og deltar i samfunnet, vil du etterlate en digital skygge. Dette ser vi videre på i neste emne.